活跃冲刺 - 看板性能优化随笔

开端
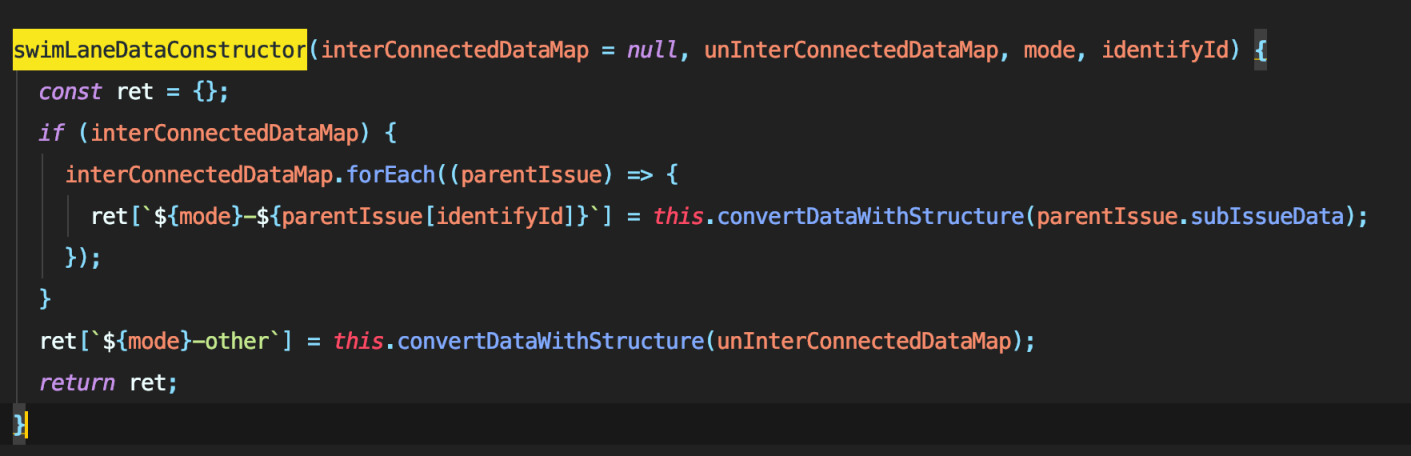
今年年初,组长要求在 Agile 看板中加入一个史诗泳道功能,其功能大致如下:
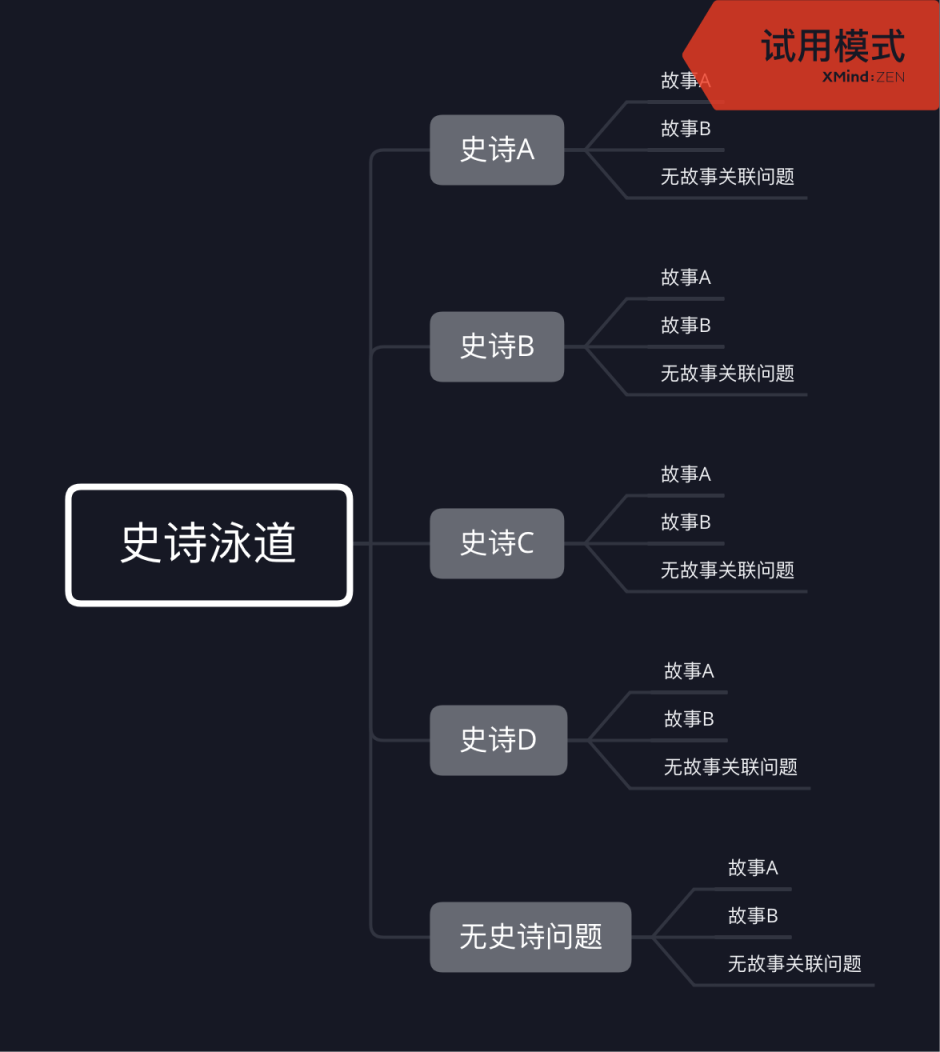
原先的代码结构中根本没有考虑过泳道之间互相嵌套的问题,而且原先的代码大部分都是这个画风:
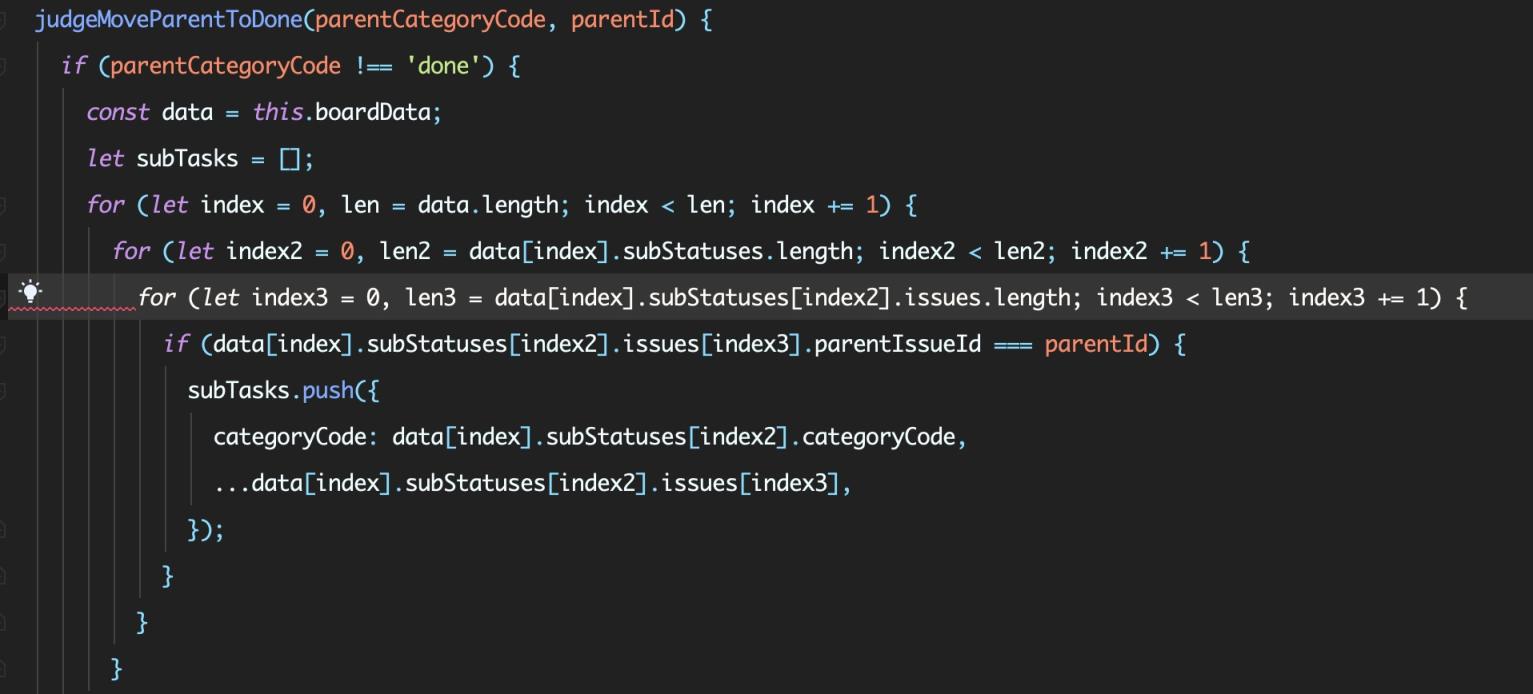
这种代码几乎是完全无法覆用的,而且多层 for 循环嵌套写出的逻辑近乎于完全无法维护。因此,我决定向组长申请重构,彻底从根源上解决代码整体结构问题
过程
在完全没有开发文档,代码注释,以及单元测试的项目中进行重构工作,是一件非常令人头疼的问题。如果不熟悉原先的代码,很容易会改出各种各样的 bug,或者做少了功能。所以我在进行代码重构前的第一步,就是整理整体代码逻辑,书写了一份简单的思维导图,用于整理原先的功能,避免重构过程中由于 bug 产生的多次返工。
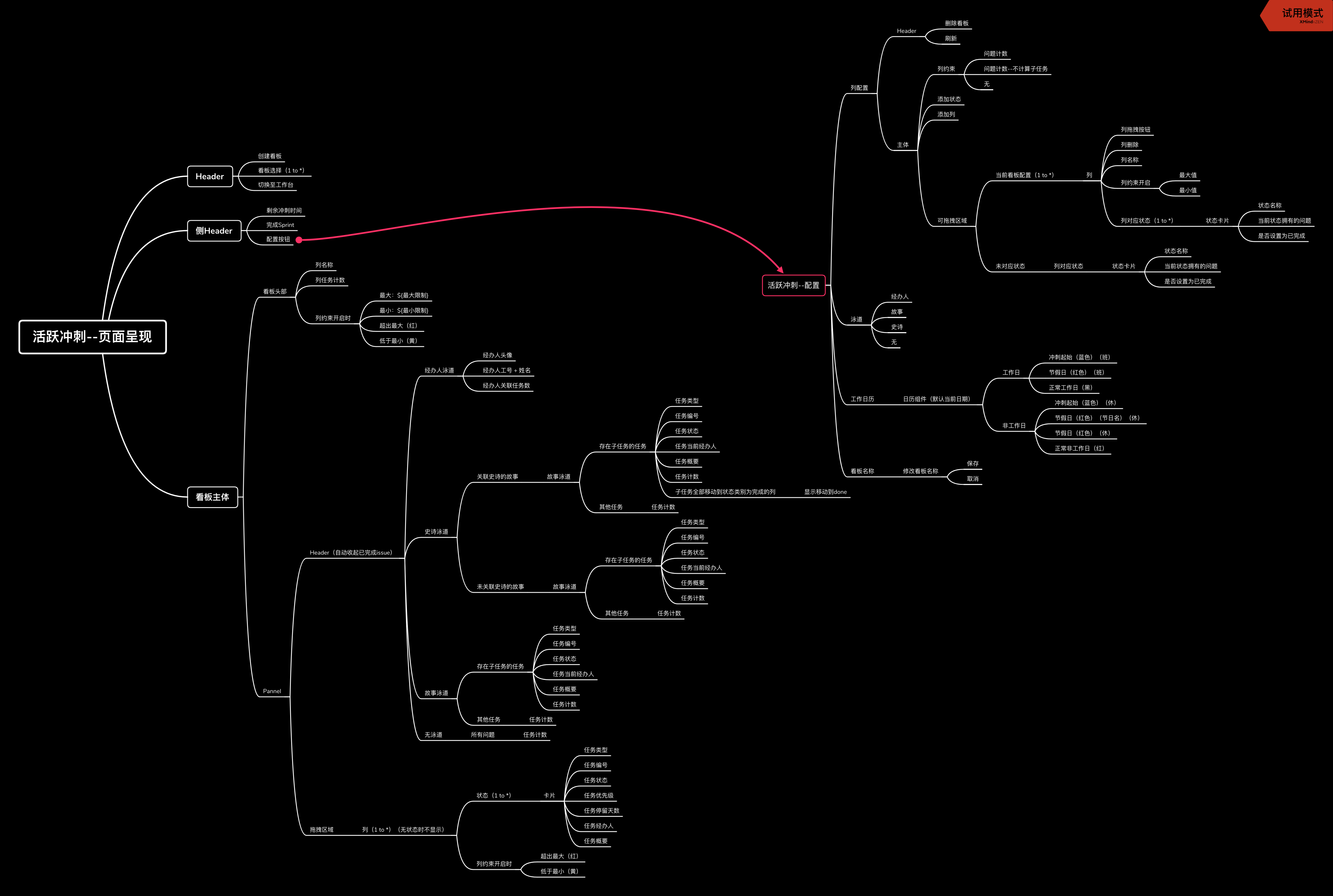
实际开发流程中,这份思维导图的功能应当被完备的单元测试所代替。书写这麽一份简单的思维导图来统计功能也是因为原先没有任何开发文档留存所导致的。
之后的问题主要集中在看板拖拽功能上,这一部分在重构过程中近乎完全重写
原先如何实现拖拽
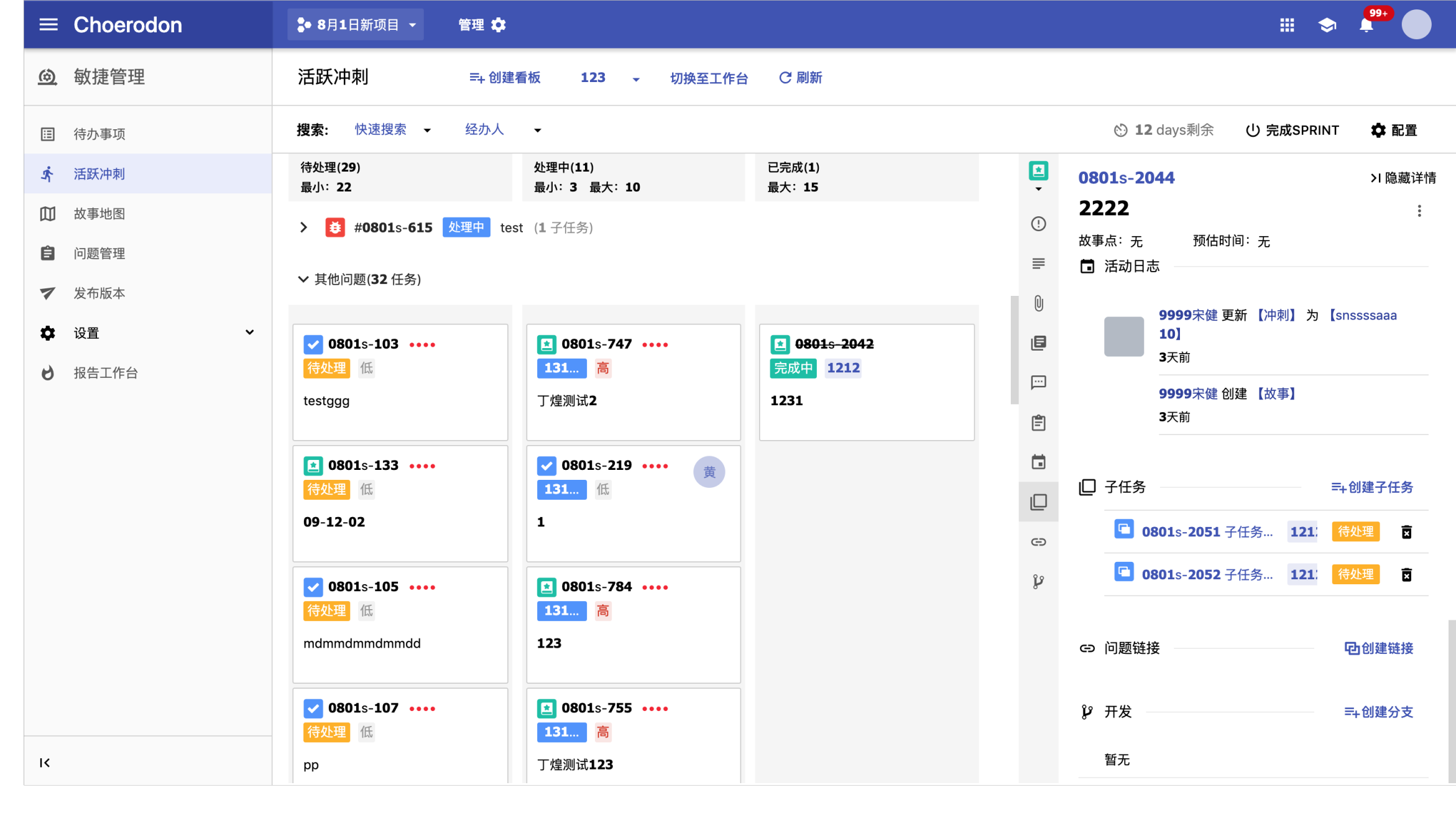
原先的开发人员在实现拖拽功能的时候,将每个列看成一个整体,存取数据时按照列存取,当拖拽操作发生时,只是将当前卡片由当前列移动至下一个列并变动排序,故事之间的关联关系通过不断遍历数组去查询。
console.log(12317491)
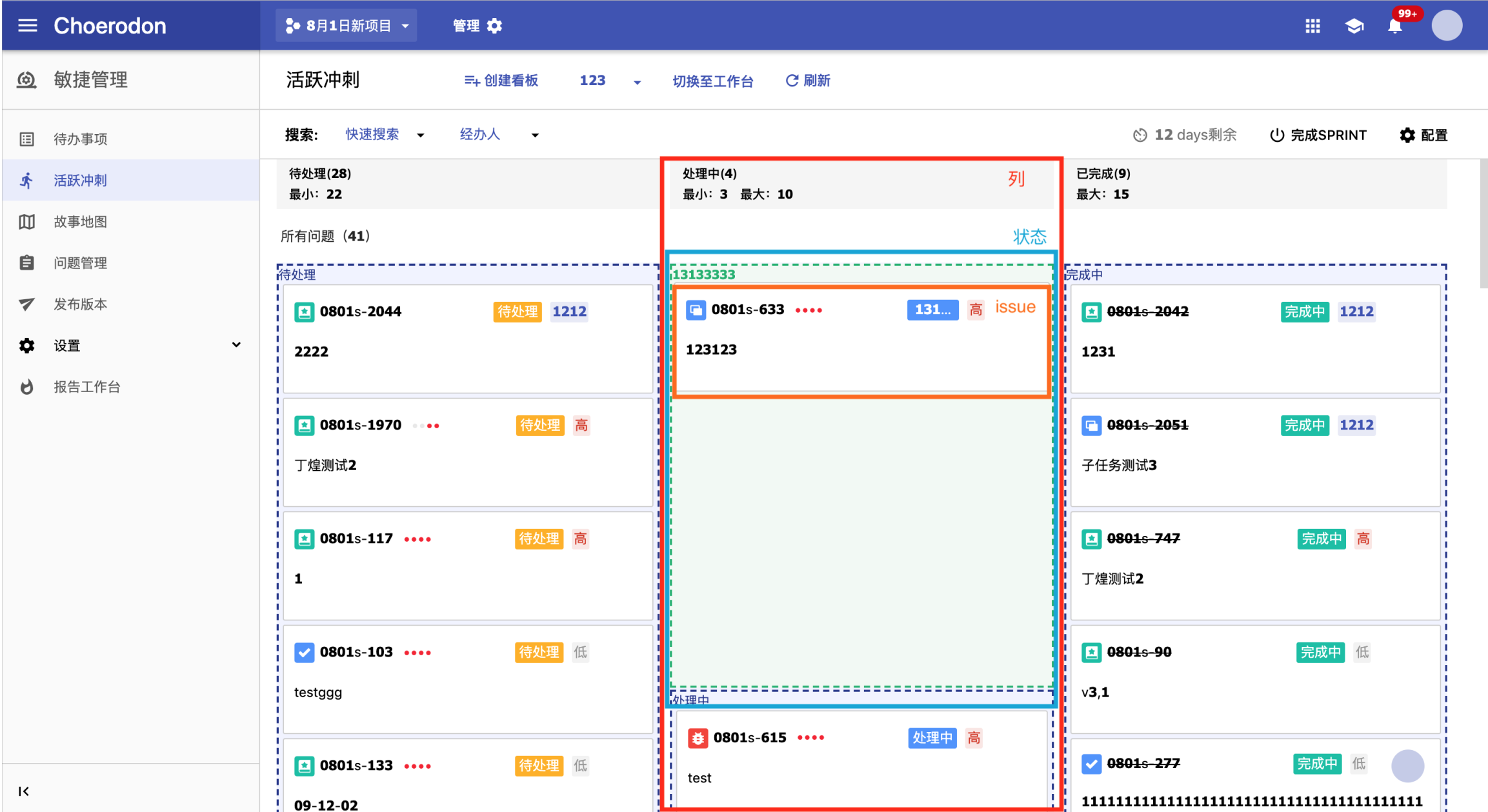
这种对拖拽的处理可以说是相当低效,如上图,我在故事泳道中拖动一个故事Pannel下的子任务,更新数据时根本不应该让其他的 Pannel 进行重新渲染。这种操作成本高昂,又没有什麽实际意义。更重要的是,这种变动会让之后维护的开发者不明所以,因为后端要求返回的数据要求是极多的,既要状态,也要故事/史诗关联关系。
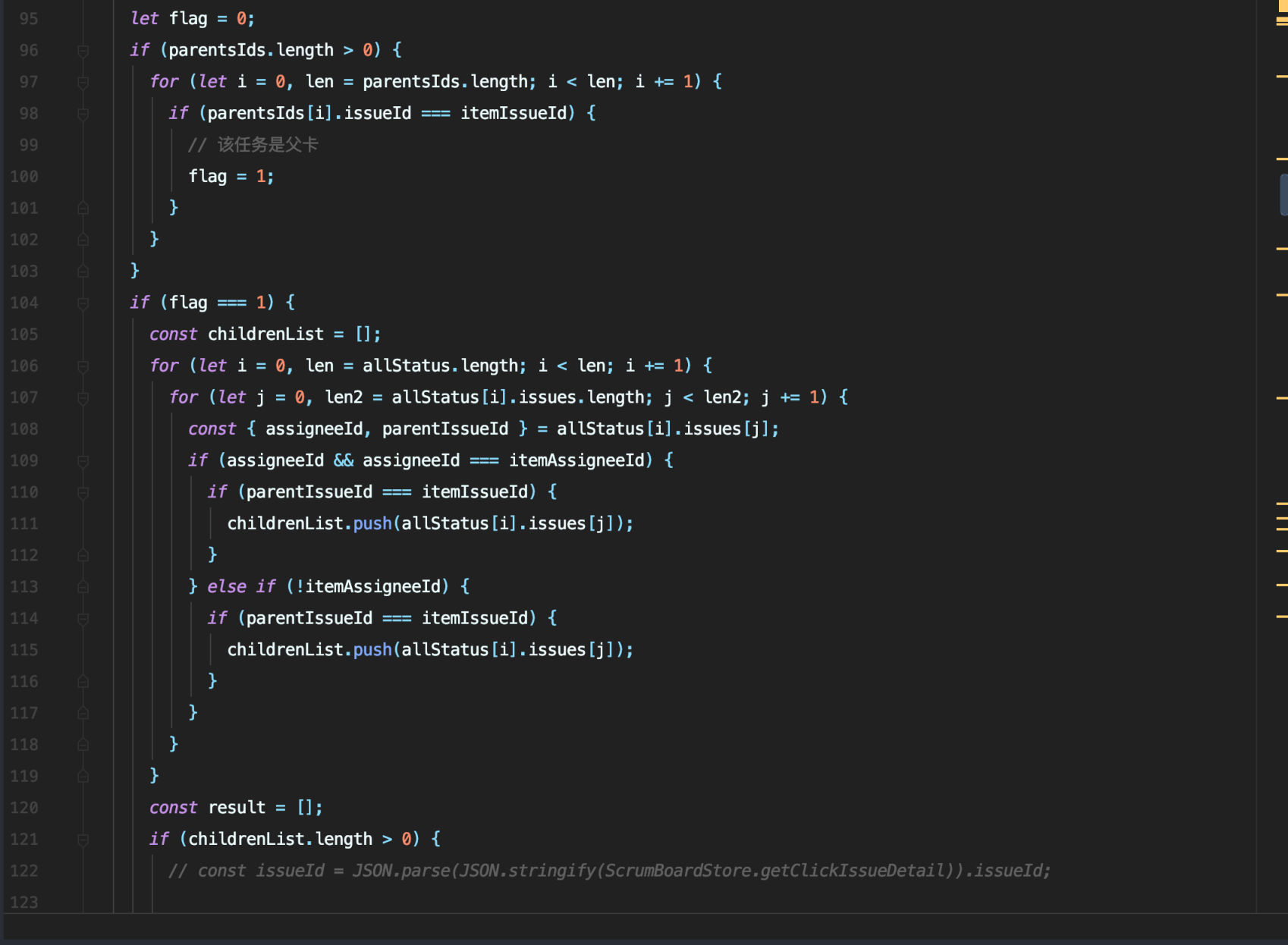
如上图所示,之前的开发者通过多个 For 循环遍历数组,做了很多次 O(n^3) 的操作,只是为了获取当前各种各样的关联关系,虽然客户机普遍不存在性能瓶颈,但是多层 For 循环本身就是不易于维护的,更不用说这种不规范的 len、len2 命名导致的理解歧义了。
原先的代码中,因为内部的处理逻辑是将列看作一个整体,所以我们每移动一张卡片都会导致两个列完全重新渲染。如果客户在待处理列放了 300 条 issue,而整个看板只有 302 条 issue,即使我们拖拽的目标列没有 issue,也会导致 React 同时更新 300 条 issue。这种情况下,是否使用 React 与 Mobx 几乎是没有意义的。因为每次拖拽约等于更新了整个页面,严重违背了 React 减少利用 Virtul-DOM 减少渲染次数的初衷。
如何对原先的代码做改进?
分析原先的看板数据结构,可以发现后端返回给我们的数据已经包含了 issue 在看板中的各种关系,而且已经用嵌套对象形成了清晰的层级结构。结合后端返回的数据结构,我们可以轻松的构建出列-状态-issue 的相关关系,无泳道(不对 issue 进行分类)情况下的整体数据呈现也随之形成了。
但是仅仅凭后端查出的这套数据,是完全没有办法满足前端通过 故事、史诗、经办人 进行数据分类的需求的,所以我们需要结合后端传回的其他数据对这些数据进行分类。
改善原先的数据结构
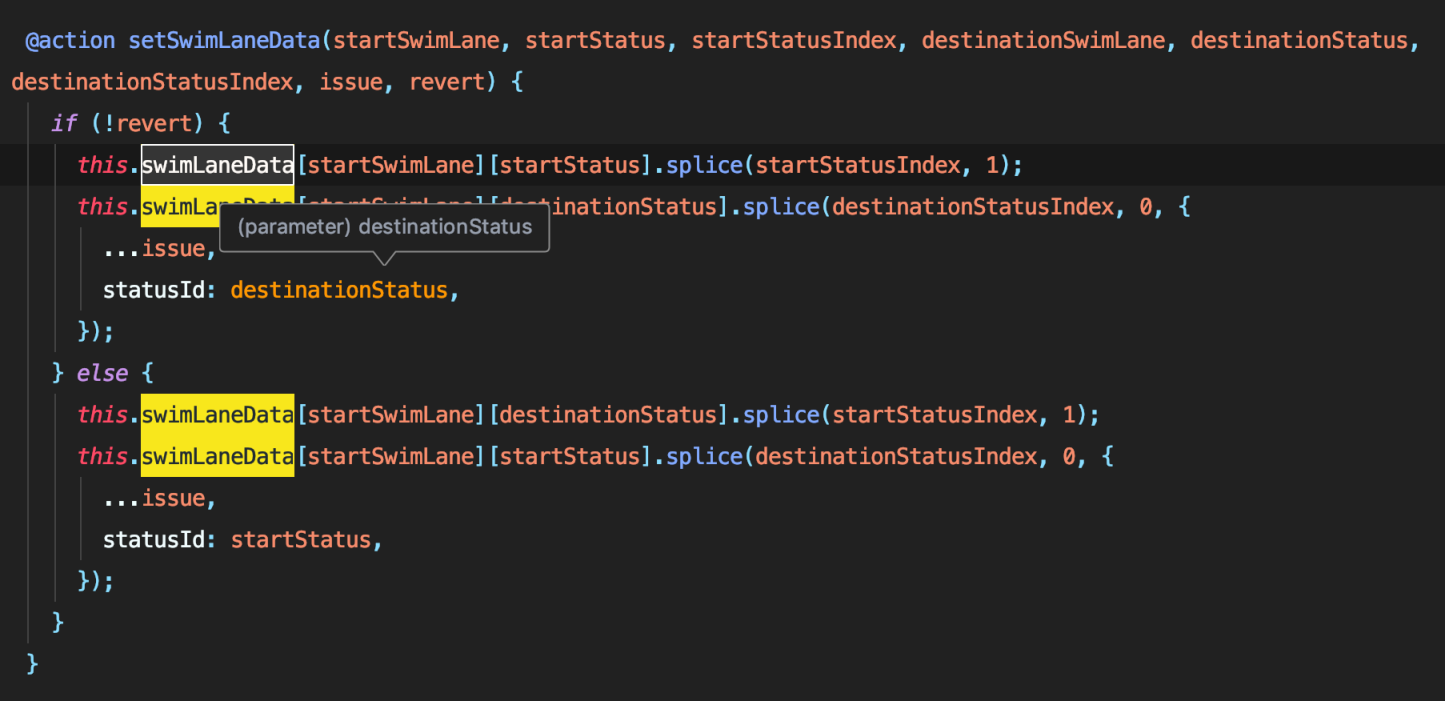
既然后端需要各种各样的关联关系,那麽我们完全可以提前存一张 issueId 与 issue 相关联的 Map,在 ComponentDidMount 时提前将后端需要的各种关联关系存进 issue,在拖拽结束通过 issueId 去查询对应的 issue 直接拿对应的关联关系。这样做虽然在初始化数据时时间覆杂度依然为 O(n^3),而且会比数组方法耗费内存,但是在获取关联关系时只需要 O(1) 的时间就能拿到对应的值,而且不必每次微小的操作都要执行 O(n^3) 覆杂度的运算。
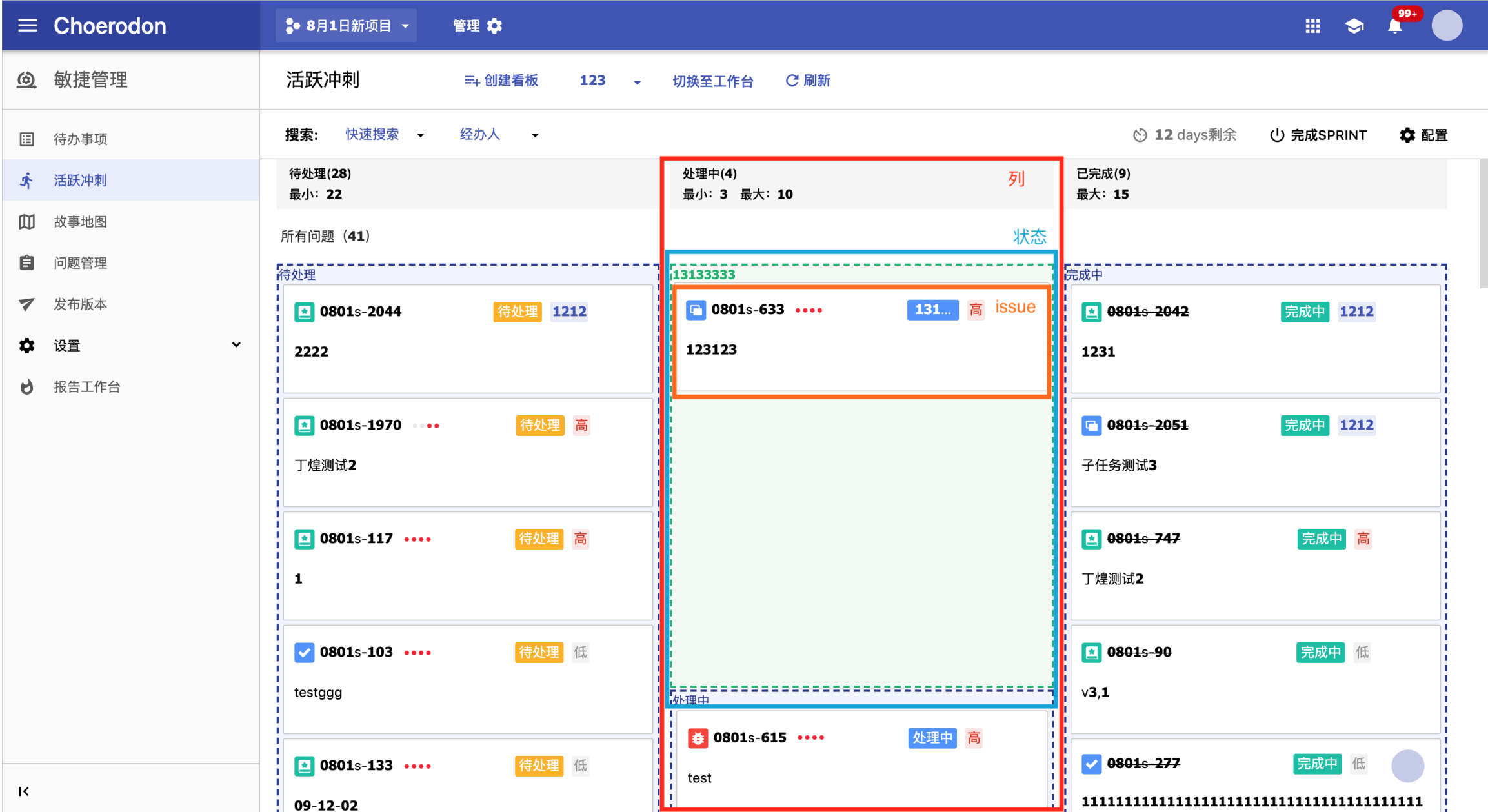
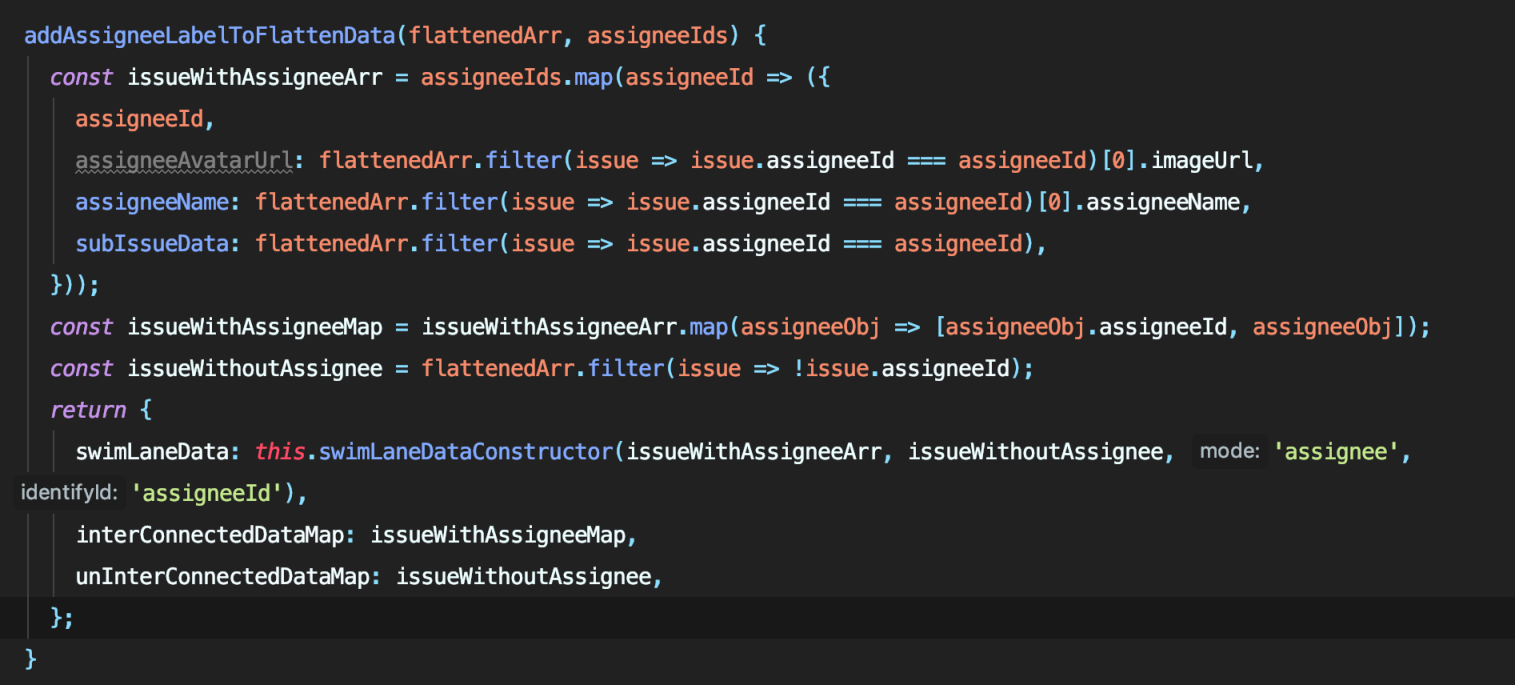
这样改进结构后,我们就可以按照 React 的设计哲学做到针对不同 Pannel 进行部分更新。如下图所示,移动位于经办人泳道下的 issue 时,我们只需要按照 ‘泳道模式-经办人 Id/other(无经办人问题)’ -> 状态 Id 查询出需要操作的数组,并进行操作即可。
去除重覆 Render
之前的代码中,一个函数调用的 action 过多,导致每执行一次 action,就会进行一次 render。这样就直接导致首屏渲染时间过长,很多时候加载瓶颈都集中在刷新后的重覆渲染中。这与 mobx 设计初衷是背道而驰的。因此,这一部分的主要工作与之前的优化一样,通过合并 action 以减轻页面的重覆渲染。
React 本身是运用
Virtual DOM来渲染整个页面的,如果渲染节点/次数过多就会导致内存占用率居高不下,GC无法正常回收多余内存。因此,规避重覆渲染也可以有效减轻内存占用率。
经过这两步优化,我们就有效的优化了 300 条 issue 时整体系统的运行效率,但是这依然存在一个问题:如果我只有 300 条 issue 不做任何分类,全部丢在待处理列中,并且开启全部泳道。这时依然需要渲染整体页面,而且帧数依然没能达到 30 帧以上。那我们需要如何针对这一种情况做优化呢?
为什麽 React-beautiful-dnd 官方组件的性能会那麽好?
在没有深入阅读 React-beautiful-dnd 的官方文档与随想之前,我一直武断的将总体帧数过低的原因归因于 React-beautiful-dnd 本身的 设计问题,但是在我 clone 了 React-beautiful-dnd 官方库,将他们提供的看板 Demo 卡片数量提升至 1500 后,我发现官方的 Demo 能够很好的处理这种极端情况,而且帧数能稳定在 60 fps。
但这一发现明显不符合常理,因为操作上千条 issue 时,本身就存在高昂的性能成本。60 fps 的前提是将每个整体渲染流程(js 执行 + css 重绘)的执行时间控制在 17ms 之内。如果 beautiful-dnd 没有采用 Virtualized List 的话,根本不可能在 17 ms 之内完成近千条 issue 的操作。也就是说,beautiful-dnd 采用了另一种不同于 Virtualized List 的神奇方案减轻渲染负担。
查阅官方文档后,我发现了这篇文章:Dragging React performance forward
这篇文章详细解释了 React-beautiful-dnd 为了做到极致拖拽性能所采取的一些独特设计方案,总体来看有以下两个技巧:
- 设定一系列事件,在开始拖拽时触发,将需要的公用
style放置在<head>标签中,避免每次都去更改大量<Draggable>组件的style - 如下图所示,每次将卡片拖拽进一个队列的时候,拖拽目标位置后的所有卡片都需要更改
Position,虽然CSS的渲染几乎没有成本,但是同时更改几百个<Draggable>组件的style难免会超出17ms的操作间隔,因此在更新组件位置时,只会更新当前可视区域内的组件style,可视区域外的组件样式会等到滚动到相应位置后再去更新。
这两个小技巧也启发了我书写了一套简单的高阶组件,用于在组件拖拽开始时更新每个列和状态的样式。
第二个小技巧在 DOM 节点极端多的情况下依然会有明显的卡顿,但是处理 500 条 issue 可以说是绰绰有余,如果卡片不覆杂的话,甚至可以处理 2500 条 issue。而 Atlassian 不采用 Virtualized List 的重要原因主要有两个:
Virtualized List无法让用户通过ctrl-f检索列表- 不希望组件过多干涉用户自己封装的组件,保证组件的易用性
当然,Atlassian 开发团队已经将 Virtualized List 提上了日程,希望给用户另一种选择。让我们拭目以待吧!
我们在使用 React-beautiful-dnd 没有注意到的盲点
首先要说的是,React-beautiful-dnd 是有一个暗坑的。虽然这个暗坑的规避方式被醒目的标记在了官方文档上,但是我们的开发明显在当初开发的时候并没有注意到这一点。具体来说就是这篇文档:Droppable,这篇文档中标题为 Recommended <Droppable /> performance optimisation 这一部分记录了一个潜在的影响性能的问题,就是 <Droppable> 组件会导致重渲染,如果没有在下一层组件设定 shouldComponentUpdate,就会导致下面的所有子组件全部重渲染。解决方案自然是在 shouldComponentUpdate 中对比 this.props 与 nextProps,相同时不执行更新。
规避数组元素变动时导致的数组全渲染
与其说规避,不如说是之前对于 React diff 算法了解不够深入导致的误解。实际上来说解决方式也非常简单,就是给每个从数组生成的 issue 设定独一无二的 key 用于识别,具体原理可以看前一篇文章中的 element-diff 部分。
尾声
新年结束后,Agile 看板服务果然不出我所料出现了严重的性能问题,客户现场甚至出现了页面完全卡死的现象。万幸的是我在年前准备了一套针对 500 条 issue 的优化方案,年后又迅速的将这个数字提升至单看板 1500 条 issue 的上限。至此,看板的重构工作算是圆满收工了。虽然现在看起来还是存在相当一部分的冗余代码,但是相对于以前代码的性能已经可以说是巨大提升了。客户机的性能虽然比服务器好得多,但是内存占用,时间覆杂度依然是我们需要考虑的一环。否则等到系统在客户现场奔溃就为时已晚了。
最后贴一下我这几个月的优化成果吧:

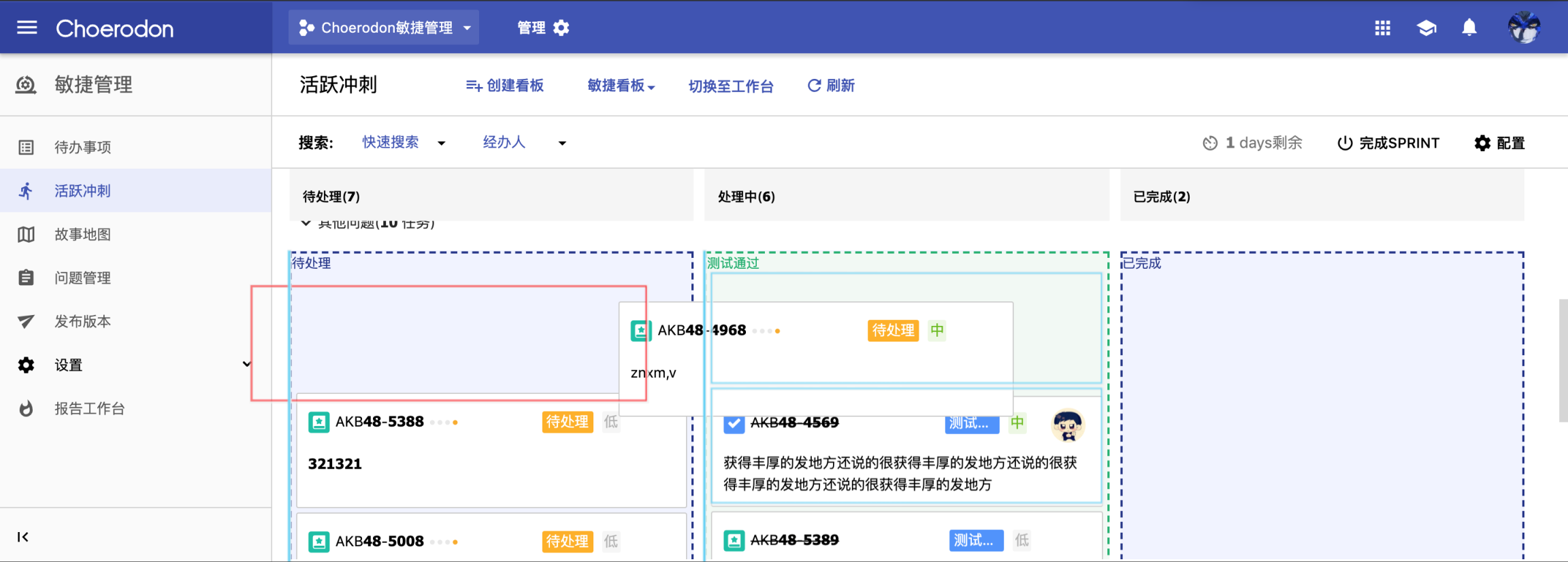
这次重构依然是留下了一部分内存泄漏的问题,后期会专门针对
Javascript内存泄漏进行研究并改进